Kafka
Kafka
QA
对 Kafka 有什么了解吗?
Kafka 特点如下。
- 高吞吐量、低延迟:kafka 每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个 topic 可以分多个 partition, consumer group 对 partition 进行 consume 操作。
- 可扩展性:kafka 集群支持热扩展。
- 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失。
- 容错性:允许集群中节点失败(若副本数量为 n,则允许 n-1 个节点失败)。
- 高并发:支持数千个客户端同时读写。
Kafka 为什么这么快
- 顺序写入优化:Kafka 将消息顺序写入磁盘,减少了磁盘的寻道时间。这种方式比随机写入更高效,因为磁盘读写头在顺序写入时只需移动一次。
- 批量处理技术:Kafka 支持批量发送消息,这意味着生产者在发送消息时可以等待直到有足够的数据积累到一定量,然后再发送。这种方法减少了网络开销和磁盘 I/O 操作的次数,从而提高了吞吐量。
- 零拷贝技术:Kafka 使用零拷贝技术,可以直接将数据从磁盘发送到网络套接字,避免了在用户空间和内核空间之间的多次数据拷贝。这大幅降低了 CPU 和内存的负载,提高了数据传输效率。
- 压缩技术:Kafka 支持对消息进行压缩,这不仅减少了网络传输的数据量,还提高了整体的吞吐量。
Kafka 的模型介绍一下,Kafka 是推送还是拉取?
消费者模型
消息由生产者发送到 Kafka 集群后,会被消费者消费。一般来说我们的消费模型有两种:推送模型(push)和拉取模型(pull)。
推送模型(push)
- 基于推送模型(push)的消息系统,有消息代理记录消费者的消费状态。
- 消息代理在将消息推送到消费者后,标记这条消息已经消费,但这种方式无法很好地保证消费被处理。
- 如果要保证消息被处理,消息代理发送完消息后,要设置状态为“已发送”,只要收到消费者的确认请求后才更新为“已消费”,这就需要代理中记录所有的消费状态,但显然这种方式不可取。
缺点如下。
- push 模式很难适应消费速率不同的消费者。
- 因为消息发送速率是由 broker 决定的,push 模式的目标是尽可能以最快速度传递消息,但是这样很容易造成 consumer 来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。
拉取模型(pull)
kafka 采用拉取模型,由消费者自己记录消费状态,每个消费者互相独立地顺序拉取每个分区的消息。
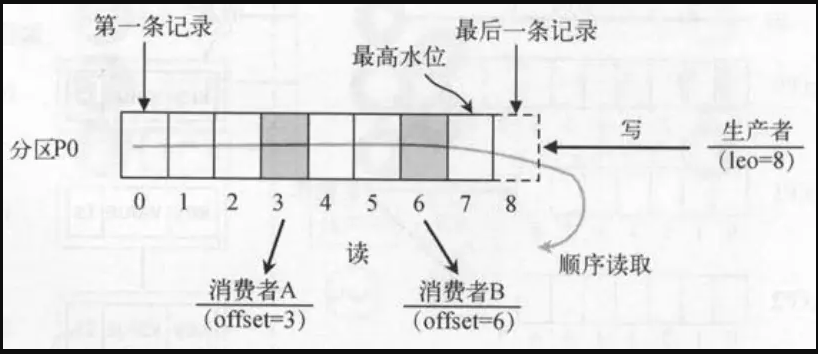
说明如下。
- 有两个消费者(不同消费者组)拉取同一个主题的消息,消费者 A 的消费进度是 3,消费者 B 的消费进度是 6。
- 消费者拉取的最大上限通过最高水位(High Watermark)控制,生产者最新写入的消息如果还没有达到备份数量,对消费者是不可见的。
- 这种由消费者控制偏移量的优点是:消费者可以按照任意的顺序消费消息。比如,消费者可以重置到旧的偏移量,重新处理之前已经消费过的消息;或者直接跳到最近的位置,从当前的时刻开始消费。
消费者组
kafka 消费者是以 consumer group 消费者组的方式工作,由一个或者多个消费者组成一个组,共同消费一个 topic。每个分区在同一时间只能由 group 中的一个消费者读取,但是多个 group 可以同时消费这个 partition。
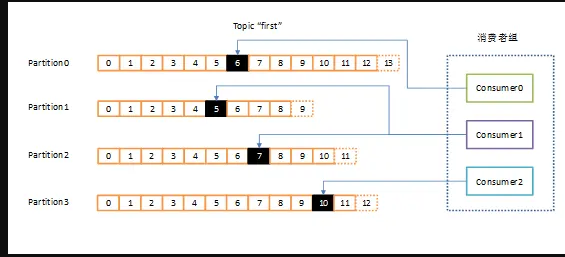
上图中,有一个由三个消费者组成的 group,有一个消费者读取主题中的两个分区,另外两个分别读取一个分区。某个消费者读取某个分区,也可以叫做某个消费者是某个分区的拥有者。
优点在于。
- 消费者可以通过水平扩展的方式同时读取大量的消息。
- 如果一个消费者失败了,那么其他的group成员会自动负载均衡读取之前失败的消费者读取的分区。
消费方式
kafka 消费者采用 pull(拉)模式从 broker 中读取数据。
pull 的优点。
- pull 模式可以根据 consumer 的消费能力以适当的速率消费消息。
缺点。
- 如果 kafka 没有数据,消费者可能会陷入循环中,一直返回空数据。针对这一点,Kafka 的消费者在消费数据时会传入一个时长参数 timeout,如果当前没有数据可供消费,consumer 会等待一段时间之后再返回,这段时长即为 timeout。
kafka 如何保证顺序读取消息
Kafka 可以保证在同一个分区内消息是有序的,生产者写入到同一分区的消息会按照写入顺序追加到分区日志文件中,消费者从分区中读取消息时也会按照这个顺序。这是 Kafka 天然具备的特性。
要在 Kafka 中保证顺序读取消息,需要结合生产者、消费者的配置以及合适的业务处理逻辑来实现。以下具体说明如何实现顺序读取消息。
- 生产者端确保消息顺序:为了保证消息写入同一分区从而确保顺序性,生产者需要将消息发送到指定分区。可以通过自定义分区器来实现,通过为消息指定相同的 Key,保证相同 Key 的消息发送到同一分区。
- 消费者端保证顺序消费:消费者在消费消息时,需要单线程消费同一分区的消息,这样才能保证按顺序处理消息。如果使用多线程消费同一分区,就无法保证消息处理的顺序性。
Kafka 本身不能保证跨分区的消息顺序性,如果需要全局的消息顺序性,通常有以下两种方法。
- 只使用一个分区:将所有消息都写入到同一个分区,消费者也只从这个分区消费消息。但这种方式会导致 Kafka 的并行处理能力下降,因为 Kafka 的性能优势在于多分区并行处理。
- 业务层面保证:在业务代码中对消息进行编号或添加时间戳等标识,消费者在消费消息后,根据这些标识对消息进行排序处理。但这种方式会增加业务代码的复杂度。
Kafka 消息积压怎么办?
- 增加消费者实例可以提高消息的消费速度,从而缓解积压问题。你需要确保消费者组中的消费者数量不超过分区数量,因为一个分区同一时间只能被一个消费者消费。
- 增加 Kafka 主题的分区数量可以提高消息的并行处理能力。在创建新分区后,你需要重新平衡消费者组,让更多的消费者可以同时消费消息。
Kafka 为什么一个分区只能由消费者组的一个消费者消费-这样设计的意义是什么?
如果两个消费者负责同一个分区,那么就意味着两个消费者同时读取分区的消息,由于消费者自己可以控制读取消息的 offset,就有可能 C1 才读到 2,而 C1 读到 1,C1 还没处理完,C2 已经读到3 了,则会造成很多浪费,因为这就相当于多线程读取同一个消息,会造成消息处理的重复,且不能保证消息的顺序。
如果有一个消费主题 topic -有一个消费组 group-topic 有 10 个分区-消费线程数和分区数的关系是怎么样的
- topic 下的一个分区只能被同一个 consumer group 下的一个 consumer 线程来消费,但反之并不成立,即一个 consumer 线程可以消费多个分区的数据,比如 Kafka 提供的 ConsoleConsumer,默认就只是一个线程来消费所有分区的数据。
- 分区数决定了同组消费者个数的上限。
- 如果你的分区数是 N,那么最好线程数也保持为 N,这样通常能够达到最大的吞吐量。超过 N 的配置只是浪费系统资源,因为多出的线程不会被分配到任何分区。
消息中间件如何做到高可用?
消息中间件如何保证高可用呢?单机是没有高可用可言的,高可用都是对集群来说的,一起看下 Kafka 的高可用吧。
Kafka 的基础集群架构,由多个 broker 组成,每个 broker 都是一个节点。当你创建一个 topic 时,它可以划分为多个 partition,而每个 partition 放一部分数据,分别存在于不同的 broker 上。也就是说,一个 topic 的数据,是分散放在多个机器上的,每个机器就放一部分数据。
有些伙伴可能有疑问,每个 partition 放一部分数据,如果对应的 broker 挂了,那这部分数据是不是就丢失了?那还谈什么高可用呢?
Kafka 0.8 之后,提供了复制品副本机制来保证高可用,即每个 partition 的数据都会同步到其它机器上,形成多个副本。然后所有的副本会选举一个 leader 出来,让 leader 去跟生产和消费者打交道,其他副本都是 follower。写数据时,leader 负责把数据同步给所有的 follower,读消息时, 直接读 leader 上的数据即可。如何保证高可用的?就是假设某个 broker 宕机,这个 broker 上的 partition 在其他机器上都有副本的。如果挂的是 leader 的 broker 呢?其他 follower 会重新选一个 leader 出来。
Kafka 和 RocketMQ 消息确认机制有什么不同?
Kafka 的消息确认机制有三种:0,1,-1。
- ACK=0:这是最不可靠的模式。生产者在发送消息后不会等待来自服务器的确认。这意味着消息可能会在发送之后丢失,而生产者将无法知道它是否成功到达服务器。
- ACK=1:这是默认模式,也是一种折衷方式。在这种模式下,生产者会在消息发送后等待来自分区领导者(leader)的确认,但不会等待所有副本(replicas)的确认。这意味着只要消息被写入分区领导者,生产者就会收到确认。如果分区领导者成功写入消息,但在同步到所有副本之前宕机,消息可能会丢失。
- ACK=-1:这是最可靠的模式。在这种模式下,生产者会在消息发送后等待所有副本的确认。只有在所有副本都成功写入消息后,生产者才会收到确认。这确保了消息的可靠性,但会导致更长的延迟。
RocketMQ 提供了三种消息发送方式:同步发送、异步发送和单向发送。
- 同步发送:是指消息发送方发出一条消息后,会在收到服务端同步响应之后才发下一条消息的通讯方式。应用场景非常广泛,例如重要通知邮件、报名短信通知、营销短信系统等。
- 异步发送:是指发送方发出一条消息后,不等服务端返回响应,接着发送下一条消息的通讯方式,但是需要实现异步发送回调接口(SendCallback)。消息发送方在发送了一条消息后,不需要等待服务端响应即可发送第二条消息。发送方通过回调接口接收服务端响应,并处理响应结果。适用于链路耗时较长,对响应时间较为敏感的业务场景,例如,视频上传后通知启动转码服务,转码完成后通知推送转码结果等。
- 单向发送:发送方只负责发送消息,不等待服务端返回响应且没有回调函数触发,即只发送请求不等待应答。此方式发送消息的过程耗时非常短,一般在微秒级别。适用于某些耗时非常短,但对可靠性要求并不高的场景,例如日志收集。
Kafka 和 RocketMQ 的 broker 架构有什么区别
- Kafka 的 broker 架构:Kafka 的 broker 架构采用了分布式的设计,每个 Kafka broker 是一个独立的服务实例,负责存储和处理一部分消息数据。Kafka 的 topic 被分区存储在不同的 broker 上,实现了水平扩展和高可用性。
- RocketMQ 的 broker 架构:RocketMQ 的 broker 架构也是分布式的,但是每个 RocketMQ broker 有主从之分,一个主节点和多个从节点组成一个 broker 集群。主节点负责消息的写入和消费者的拉取,从节点负责消息的复制和消费者的负载均衡,提高了消息的可靠性和可用性。
Kafka 稳定性怎么保证
回答来源于 DeepSeek。 简介回答如下,详细可以文 DeepSeek "Kafka 稳定性怎么保证,这个帮我整理为面试如何回答的思路"。
Kafka 的稳定性主要通过 数据冗余、故障自动恢复 和 生产消费端优化保障。
- 数据层面:采用多副本(Replica)+ ISR 机制,确保数据不丢失;生产端配置 acks=all 保证写入可靠性。
- 高可用:Leader 宕机时,Controller 秒级切换新 Leader;消费者通过 Offset 提交避免重复消费。
- 运维:监控磁盘、网络、副本同步状态,并做容量规划。
&emsp:如果有示例则举例,如我们在 XX 业务中,通过优化 min.insync.replicas=2 和镜像同步,实现了全年 99.99% 可用性。
Kafka 消费者组再均衡问题
为什么 Kafka 能支持多个消费者组重复消费数据?
- 机制:通过消费组隔离 Offset + 分区并行设计实现数据复用。
- 优势:解耦生产消费、支撑实时/离线混合场景。
- 案例:举例实时数仓或事件驱动架构中的多组消费场景。
- 注意事项:提及资源消耗和 Offset 管理。
多读的典型应用案例。
- 实时数仓。
- 同一份用户行为日志同时被 Flink 实时计算(消费组 A)、Spark 离线分析(消费组 B)。
- 事件驱动架构。
- 订单创建事件被库存服务(消费组 A)扣减库存、营销服务(消费组 B)发放优惠券。
- 数据迁移与回溯。
- 旧系统消费组处理实时流量,新系统消费组重放历史数据验证逻辑。
Kafka 零拷贝原理
面试一句话:Kafka 通过 sendfile() 和 mmap 实现零拷贝,省去用户态数据拷贝,大幅提升 I/O 效率,适合高吞吐场景。
4 次拷贝说明如下。
| 步骤 | 传统 I/O | 零拷贝(如 Kafka) |
|---|---|---|
| 1. 磁盘 → 内核缓冲区 | ✅ DMA 拷贝 | ✅ DMA 拷贝 |
| 2. 内核 → 用户态缓冲区 | ✅ CPU 拷贝(数据从内核态复制到用户态) | ❌ 跳过(直接在内核态处理) |
| 3. 用户态 → Socket 缓冲区 | ✅ CPU 拷贝(数据从用户态复制到内核 Socket 缓冲区) | ❌ 跳过(通过 sendfile() 直接关联到网卡) |
| 4. Socket → 网卡 | ✅ DMA 拷贝 | ✅ DMA 拷贝 |
| 总拷贝次数 | 4 次 (2 次 DMA + 2 次 CPU) | 2 次 (仅 DMA 拷贝,无 CPU 参与) |
| 系统调用 | read() + write()(需切换用户态/内核态) | sendfile() 或 mmap(全程内核态操作) |
| CPU 开销 | 高(频繁数据拷贝和上下文切换) | 极低(避免冗余拷贝) |
| 适用场景 | 通用文件传输 | 高性能场景 (如 Kafka、Nginx 等大数据量传输) |