8 对象
8 对象
TIP
本小节主要介绍以下知识:
- 对象相关知识。
概述
在前面的数个章节里,我们陆续介绍了 Redis 用到的所有主要数据结构,比如简单动态字符串(SDS)、双端链表、字典、压缩列表、整数集合等等。
Redis 并没有直接使用这些数据结构来实现键值对数据库,而是基于这些数据结构创建了一个对象系统,这个系统包括字符串对象、列表对象、哈希对象、集合对象和有序集合对象这五种的对象,每种对象都用到了至少一种我们前面所介绍的数据结构。
通过这五种不同类型的对象,Redis 可以在执行命令之前,根据对象的类型来判断一个对象是否可以执行给定的命令。使用对象的一个好处是,我们可以针对不同的使用场景,为对象设置多种不同的数据结构实现,从而优化对象在不同场景下的使用效率。
除此之外,Redis 的对象系统还实现了基于引用计数技术的内存回收机制,当程序不再使用某个对象的时候,这个对象所占用的内存就会被自动释放;另外,Redis 还通过引用计数技术实现了对象共享机制,这一机制可以在适当的条件下,通过让多个数据库键共享同一个对象来节约内存。
最后,Redis 的对象带有访问时间记录信息,该信息可以用于计算数据库键的空转时长,在服务器启用了 maxmemory 功能的情况下,空转时长较大的那些键可能会优先被服务器删除。
对象的类型和编码
Redis 使用对象来表示数据库中的键和值,每次当我们在 Redis 的数据库中新创建一个键值对时,我们至少会创建两个对象,一个对象用作键值对的键(键对象),另一个对象用作键值对的值(值对象)。
Redis 中的每个对象都由一个 redisObject 结构表示 该结构中和保存数据有关的三个属性分别是 type 属性、encoding 属性和 ptr 属性。
typedef struct redisObject {
// 类型
unsigned type:4;
// 编码
unsigned encoding:4;
// 指向底层实现数据结构的指针
void *ptr;
// ...
} robj;
类型
对象的 type 属性记录了对象的类型,这个属性的值可以是表 8-1 列出的常量的其中一个。
| 类型常量 | 对象的名称 |
|---|---|
| REDIS_STRING | 字符串对象 |
| REDIS_LIST | 列表对象 |
| REDIS_HASH | 哈希对象 |
| REDIS_SET | 集合对象 |
| REDIS_ZSET | 有序集合对象 |
对于 Redis 数据库保存的键值对来说,键总是一个字符串对象,而值则可以是字符串对象、列表对象、哈希对象、集合对象或者有序集合对象的其中一种, 因此:
- 当我们称呼一个数据库键为“字符串键”时,我们指的是“这个数据库键所对应的值为字符串对象”;
- 当我们称呼一个键为“列表键”时,我们指的是“这个数据库键所对应的值为列表对象”。
诸如此类。
TYPE 命令的实现方式也与此类似,当我们对一个数据库键执行 TYPE 命令时,命令返回的结果为数据库键对应的值对象的类型,而不是键对象的类型:
# 键为字符串对象,值为字符串对象
redis> SET msg "hello world"
OK
redis> TYPE msg
string
表 8-2 列出了 TYPE 命令在面对不同类型的值对象时所产生的输出。
| 对象 | 对象 type 属性的值 | TYPE 命令的输出 |
|---|---|---|
| 字符串对象 | REDIS_STRING | "string" |
| 列表对象 | REDIS_LIST | "list" |
| 哈希对象 | REDIS_HASH | "hash" |
| 集合对象 | REDIS_SET | "set" |
| 有序集合对象 | REDIS_ZSET | "zset" |
编码和底层实现
对象的 ptr 指针指向对象的底层实现数据结构,而这些数据结构由对象的 encoding 属性决定。
encoding 属性记录了对象所使用的编码,也即是说这个对象使用了什么数据结构作为对象的底层实现,这个属性的值可以是表 8-3 列出的常量的其中一个。
| 编码常量 | 编码所对应的底层数据结构 |
|---|---|
| REDIS_ENCODING_INT | long 类型的整数 |
| REDIS_ENCODING_EMBSTR | embstr 编码的简单动态字符串 |
| REDIS_ENCODING_RAW | 简单动态字符串 |
| REDIS_ENCODING_HT | 字典 |
| REDIS_ENCODING_LINKEDLIST | 双端链表 |
| REDIS_ENCODING_ZIPLIST | 压缩列表 |
| REDIS_ENCODING_INTSET | 整数集合 |
| REDIS_ENCODING_SKIPLIST | 跳跃表和字典 |
每种类型的对象都至少使用了两种不同的编码, 表 8-4 列出了每种类型的对象可以使用的编码。
| 类型 | 编码 | 对象 |
|---|---|---|
| REDIS_STRING | REDIS_ENCODING_INT | 使用整数值实现的字符串对象。 |
| REDIS_STRING | REDIS_ENCODING_EMBSTR | 使用 embstr 编码的简单动态字符串实现的字符串对象。 |
| REDIS_STRING | REDIS_ENCODING_RAW | 使用简单动态字符串实现的字符串对象。 |
| REDIS_LIST | REDIS_ENCODING_ZIPLIST | 使用压缩列表实现的列表对象。 |
| REDIS_LIST | REDIS_ENCODING_LINKEDLIST | 使用双端链表实现的列表对象。 |
| REDIS_HASH | REDIS_ENCODING_ZIPLIST | 使用压缩列表实现的哈希对象。 |
| REDIS_HASH | REDIS_ENCODING_HT | 使用字典实现的哈希对象。 |
| REDIS_SET | REDIS_ENCODING_INTSET | 使用整数集合实现的集合对象。 |
| REDIS_SET | REDIS_ENCODING_HT | 使用字典实现的集合对象。 |
| REDIS_ZSET | REDIS_ENCODING_ZIPLIST | 使用压缩列表实现的有序集合对象。 |
| REDIS_ZSET | REDIS_ENCODING_SKIPLIST | 使用跳跃表和字典实现的有序集合对象。 |
使用 OBJECT ENCODING 命令可以查看一个数据库键的值对象的编码:
127.0.0.1:6379> set msg "hello wrold"
OK
127.0.0.1:6379> object encoding msg
"embstr"
表 8-5 列出了不同编码的对象所对应的 OBJECT ENCODING 命令输出。
| 对象所使用的底层数据结构 | 编码常量 | OBJECT ENCODING 命令输出 |
|---|---|---|
| 整数 | REDIS_ENCODING_INT | "int" |
| embstr 编码的简单动态字符串(SDS) | REDIS_ENCODING_EMBSTR | "embstr" |
| 简单动态字符串 | REDIS_ENCODING_RAW | "raw" |
| 字典 | REDIS_ENCODING_HT | "hashtable" |
| 双端链表 | REDIS_ENCODING_LINKEDLIST | "linkedlist" |
| 压缩列表 | REDIS_ENCODING_ZIPLIST | "ziplist" |
| 整数集合 | REDIS_ENCODING_INTSET | "intset" |
| 跳跃表和字典 | REDIS_ENCODING_SKIPLIST | "skiplist" |
通过 encoding 属性来设定对象所使用的编码,而不是为特定类型的对象关联一种固定的编码,极大地提升了 Redis 的灵活性和效率,因为 Redis 可以根据不同的使用场景来为一个对象设置不同的编码,从而优化对象在某一场景下的效率。
举个例子,在列表对象包含的元素比较少时,Redis 使用压缩列表作为列表对象的底层实现:
- 因为压缩列表比双端链表更节约内存,并且在元素数量较少时,在内存中以连续块方式保存的压缩列表比起双端链表可以更快被载入到缓存中;
- 随着列表对象包含的元素越来越多,使用压缩列表来保存元素的优势逐渐消失时,对象就会将底层实现从压缩列表转向功能更强、也更适合保存大量元素的双端链表上面。
字符串对象
字符串对象的编码可以是 int、raw 或者 embstr。
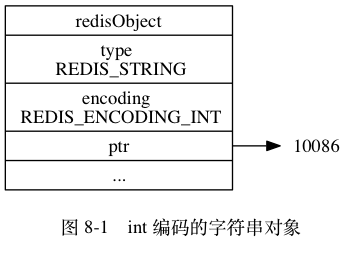
如果一个字符串对象保存的是整数值,并且这个整数值可以用 long 类型来表示,那么字符串对象会将整数值保存在字符串对象结构的 ptr 属性里面(将 void* 转换成 long ),并将字符串对象的编码设置为 int。
举个例子,如果我们执行以下 SET 命令,那么服务器将创建一个如图 8-1 所示的 int 编码的字符串对象作为 number 键的值:
127.0.0.1:6379> SET number 10086
OK
127.0.0.1:6379> object encoding number
"int"
如果字符串对象保存的是一个字符串值,并且这个字符串值的长度大于 39 字节,那么字符串对象将使用一个简单动态字符串(SDS)来保存这个字符串值,并将对象的编码设置为 raw。 举个例子,如果我们执行以下命令,那么服务器将创建一个如图 8-2 所示的 raw 编码的字符串对象作为 story 键的值:
redis> SET story "Long, long, long ago there lived a king ..."
OK
redis> STRLEN story
(integer) 43
redis> OBJECT ENCODING story
"raw" # 用 Redis 6 测试时是 empstr

如果字符串对象保存的是一个字符串值,并且这个字符串值的长度小于等于 39 字节,那么字符串对象将使用 embstr 编码的方式来保存这个字符串值。
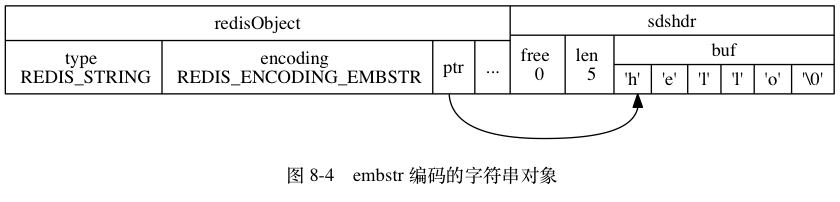
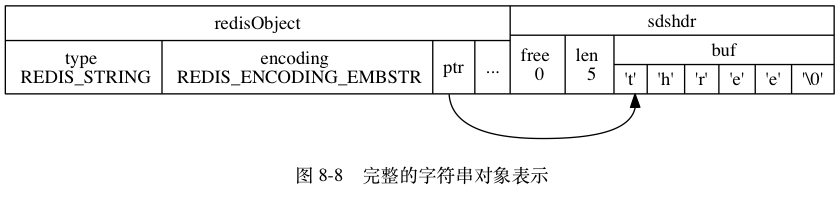
embstr 编码是专门用于保存短字符串的一种优化编码方式,这种编码和 raw 编码一样,都使用 redisObject 结构和 sdshdr 结构来表示字符串对象,但 raw 编码会调用两次内存分配函数来分别创建 redisObject 结构和 sdshdr 结构,而 embstr 编码则通过调用一次内存分配函数来分配一块连续的空间,空间中依次包含 redisObject 和 sdshdr 两个结构,如图 8-3 所示。

embstr 编码的字符串对象在执行命令时,产生的效果和 raw 编码的字符串对象执行命令时产生的效果是相同的,但使用 embstr 编码的字符串对象来保存短字符串值有以下好处:
embstr编码将创建字符串对象所需的内存分配次数从raw编码的两次降低为一次。- 释放
embstr编码的字符串对象只需要调用一次内存释放函数,而释放raw编码的字符串对象需要调用两次内存释放函数。 - 因为
embstr编码的字符串对象的所有数据都保存在一块连续的内存里面,所以这种编码的字符串对象比起raw编码的字符串对象能够更好地利用缓存带来的优势。
作为例子,以下命令创建了一个 embstr 编码的字符串对象作为 msg 键的值,值对象的样子如图 8-4 所示:
redis> SET msg "hello"
OK
redis> OBJECT ENCODING msg
"embstr"
最后要说的是,可以用 long、double 类型表示的浮点数在 Redis 中也是作为字符串值来保存的:如果我们要保存一个浮点数到字符串对象里面,那么程序会先将这个浮点数转换成字符串值,然后再保存起转换所得的字符串值。 举个例子,执行以下代码将创建一个包含 3.14 的字符串表示 "3.14" 的字符串对象:
redis> SET pi 3.14
OK
redis> OBJECT ENCODING pi
"embstr"
在有需要的时候,程序会将保存在字符串对象里面的字符串值转换回浮点数值,执行某些操作,然后再将执行操作所得的浮点数值转换回字符串值,并继续保存在字符串对象里面。 举个例子,如果我们执行以下代码的话:
redis> INCRBYFLOAT pi 2.0
"5.14"
redis> OBJECT ENCODING pi
"embstr"
那么程序首先会取出字符串对象里面保存的字符串值 "3.14" ,将它转换回浮点数值 3.14,然后把 3.14 和 2.0 相加得出的值 5.14 转换成字符串 "5.14" ,并将这个 "5.14" 保存到字符串对象里面。 表 8-6 总结并列出了字符串对象保存各种不同类型的值所使用的编码方式。
| 值 | 编码 |
|---|---|
可以用 long 类型保存的整数。 | int |
可以用 long double 类型保存的浮点数。 | embstr 或者 raw |
字符串值, 或者因为长度太大而没办法用 long 类型表示的整数, 又或者因为长度太大而没办法用 long double 类型表示的浮点数。 | embstr 或者 r |
编码的转换
int 编码的字符串对象和 embstr 编码的字符串对象在条件满足的情况下,会被转换为 raw 编码的字符串对象。
对于 int 编码的字符串对象来说,如果我们向对象执行了一些命令,使得这个对象保存的不再是整数值,而是一个字符串值,那么字符串对象的编码将从 int 变为 raw。例如使用 APPEND number " is a good number",操作的执行结果就是一个 raw 编码的、保存了字符串值的字符串对象。
另外,因为 Redis 没有为 embstr 编码的字符串对象编写任何相应的修改程序(只有 int 编码的字符串对象和 raw 编码的字符串对象有这些程序),所以 embstr 编码的字符串对象实际上是只读的:当我们对 embstr 编码的字符串对象执行任何修改命令时,程序会先将对象的编码从 embstr 转换成 raw,然后再执行修改命令;因为这个原因,embstr 编码的字符串对象在执行修改命令之后,总会变成一个 raw 编码的字符串对象。
以下代码展示了一个 embstr 编码的字符串对象在执行 APPEND 命令之后,对象的编码从 embstr 变为 raw 的例子:
redis> SET msg "hello world"
OK
redis> OBJECT ENCODING msg
"embstr"
redis> APPEND msg " again!"
(integer) 18
redis> OBJECT ENCODING msg
"raw"
字符串命令的实现
因为字符串键的值为字符串对象,所以用于字符串键的所有命令都是针对字符串对象来构建的,表 8-7 列举了其中一部分字符串命令,以及这些命令在不同编码的字符串对象下的实现方法。 字符串命令的实现参考 字符串命令的实现
列表对象
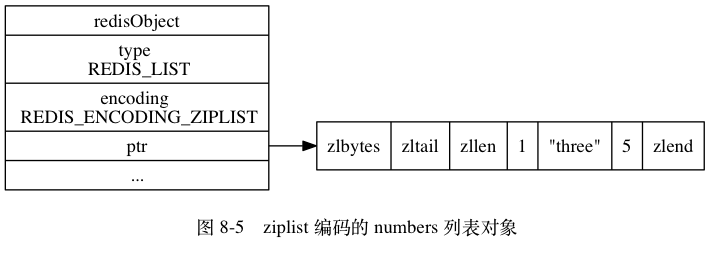
列表对象的编码可以是 ziplist 或者 linkedlist。 ziplist 编码的列表对象使用压缩列表作为底层实现,每个压缩列表节点(entry)保存了一个列表元素。 举个例子,如果我们执行以下 RPUSH 命令,那么服务器将创建一个列表对象作为 numbers 键的值:
redis> RPUSH numbers 1 "three" 5
(integer) 3
如果 numbers 键的值对象使用的是 ziplist 编码,这个这个值对象将会是图 8-5 所展示的样子。
另一方面,linkedlist 编码的列表对象使用双端链表作为底层实现,每个双端链表节点(node)都保存了一个字符串对象,而每个字符串对象都保存了一个列表元素。 举个例子,如果前面所说的 numbers 键创建的列表对象使用的不是 ziplist 编码,而是 linkedlist 编码,那么 numbers 键的值对象将是图 8-6 所示的样子。
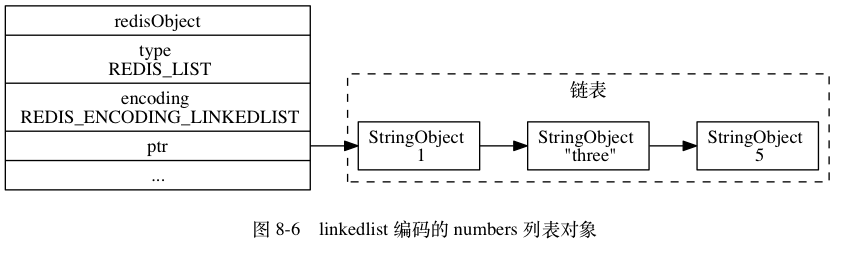
注意,linkedlist 编码的列表对象在底层的双端链表结构中包含了多个字符串对象,这种嵌套字符串对象的行为在稍后介绍的哈希对象、集合对象和有序集合对象中都会出现,字符串对象是 Redis 五种类型的对象中唯一一种会被其他四种类型对象嵌套的对象。
编码转换
当列表对象可以同时满足以下两个条件时,列表对象使用 ziplist 编码:
- 列表对象保存的所有字符串元素的长度都小于 64 字节;
- 列表对象保存的元素数量小于 512 个。
不能满足这两个条件的列表对象需要使用 linkedlist 编码。
TIP
以上两个条件的上限值是可以修改的,具体请看配置文件中关于 list-max-ziplist-value 选项和 list-max-ziplist-entries 选项的说明。
对于使用 ziplist 编码的列表对象来说,当使用 ziplist 编码所需的两个条件的任意一个不能被满足时,对象的编码转换操作就会被执行:原本保存在压缩列表里的所有列表元素都会被转移并保存到双端链表里面,对象的编码也会从 ziplist 变为 linkedlist。
官方的两个类型转换示例略。
列表命令的实现
因为列表键的值为列表对象,所以用于列表键的所有命令都是针对列表对象来构建的。 列表命令的实现参考 列表命令的实现
哈希对象
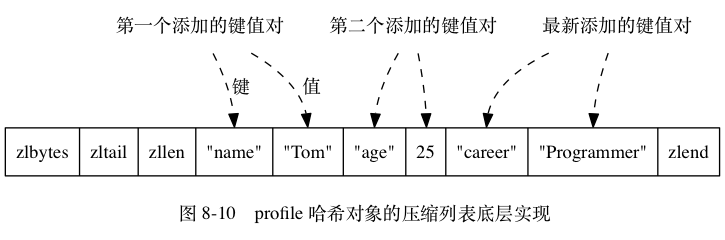
哈希对象的编码可以是 ziplist 或者 hashtable。 ziplist 编码的哈希对象使用压缩列表作为底层实现,每当有新的键值对要加入到哈希对象时,程序会先将保存了键的压缩列表节点推入到压缩列表表尾,然后再将保存了值的压缩列表节点推入到压缩列表表尾,因此:
- 保存了同一键值对的两个节点总是紧挨在一起,保存键的节点在前,保存值的节点在后;
- 先添加到哈希对象中的键值对会被放在压缩列表的表头方向,而后来添加到哈希对象中的键值对会被放在压缩列表的表尾方向。
举个例子,如果我们执行以下 HSET 命令,那么服务器将创建一个列表对象作为 profile 键的值:
redis> HSET profile name "Tom"
(integer) 1
redis> HSET profile age 25
(integer) 1
redis> HSET profile career "Programmer"
(integer) 1
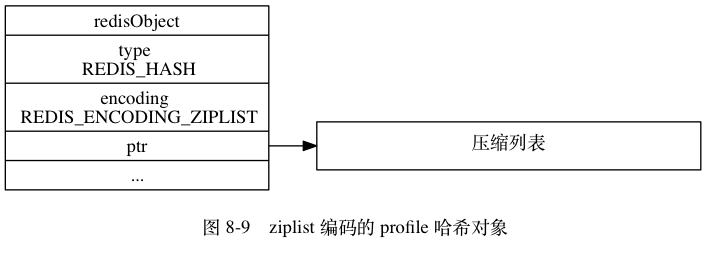
如果 profile 键的值对象使用的是 ziplist 编码, 那么这个值对象将会是图 8-9 所示的样子,其中对象所使用的压缩列表如图 8-10 所示。
另一方面,hashtable 编码的哈希对象使用字典作为底层实现,哈希对象中的每个键值对都使用一个字典键值对来保存:
- 字典的每个键都是一个字符串对象,对象中保存了键值对的键;
- 字典的每个值都是一个字符串对象,对象中保存了键值对的值。
举个例子,如果前面 profile 键创建的不是 ziplist 编码的哈希对象,而是 hashtable 编码的哈希对象,那么这个哈希对象应该会是图 8-11 所示的样子。 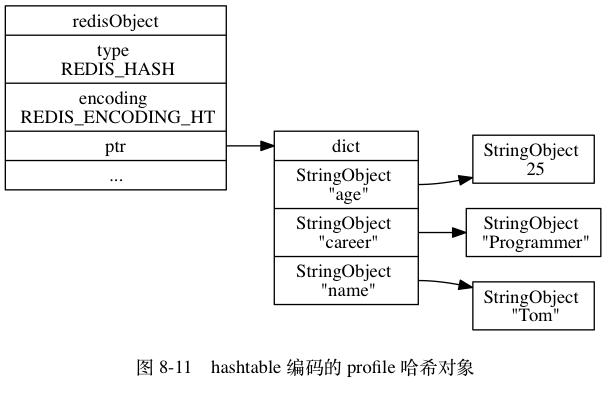
编码转换
当哈希对象可以同时满足以下两个条件时,哈希对象使用 ziplist 编码:
- 哈希对象保存的所有键值对的键和值的字符串长度都小于 64 字节;
- 哈希对象保存的键值对数量小于 512 个。
不能满足这两个条件的哈希对象需要使用 hashtable 编码。
TIP
这两个条件的上限值是可以修改的,具体请看配置文件中关于 hash-max-ziplist-value 选项和 hash-max-ziplist-entries 选项的说明。
对于使用 ziplist 编码的列表对象来说,当使用 ziplist 编码所需的两个条件的任意一个不能被满足时,对象的编码转换操作就会被执行:原本保存在压缩列表里的所有键值对都会被转移并保存到字典里面,对象的编码也会从 ziplist 变为 hashtable。 官方的三个类型转换示例略。
哈希命令的实现
因为哈希键的值为哈希对象,所以用于哈希键的所有命令都是针对哈希对象来构建的,表 8-9 列出了其中一部分哈希键命令, 以及这些命令在不同编码的哈希对象下的实现方法。 因为哈希键的值为哈希对象,所以用于哈希键的所有命令都是针对哈希对象来构建的。 一部分哈希键命令实现参考 一部分哈希键命令
集合对象
集合对象的编码可以是 intset 或者 hashtable。
intset 编码的集合对象使用整数集合作为底层实现,集合对象包含的所有元素都被保存在整数集合里面。
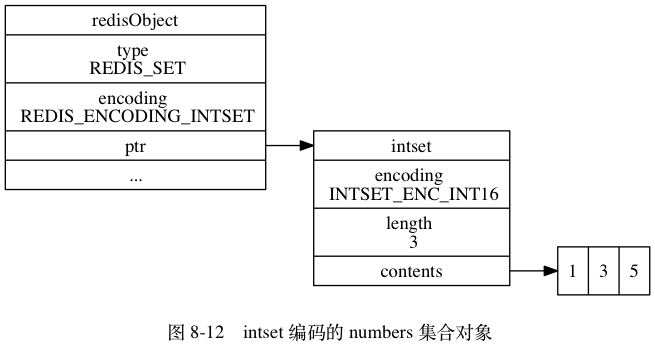
举个例子,以下代码将创建一个如图 8-12 所示的 intset 编码集合对象:
redis> SADD numbers 1 3 5
(integer) 3
另一方面,hashtable 编码的集合对象使用字典作为底层实现,字典的每个键都是一个字符串对象,每个字符串对象包含了一个集合元素,而字典的值则全部被设置为 NULL。
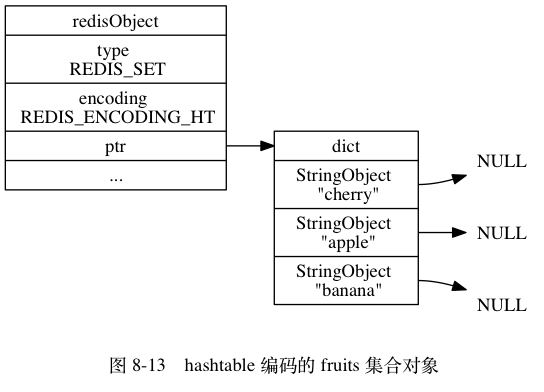
举个例子,以下代码将创建一个如图 8-13 所示的 hashtable 编码集合对象:
redis> SADD fruits "apple" "banana" "cherry"
(integer) 3
编码的转换
当集合对象可以同时满足以下两个条件时,对象使用 intset 编码:
- 集合对象保存的所有元素都是整数值;
- 集合对象保存的元素数量不超过 512 个。
不能满足这两个条件的集合对象需要使用 hashtable 编码。
TIP
第二个条件的上限值是可以修改的,具体请看配置文件中关于 set-max-intset-entries 选项的说明。
对于使用 intset 编码的集合对象来说,当使用 intset 编码所需的两个条件的任意一个不能被满足时,对象的编码转换操作就会被执行:原本保存在整数集合中的所有元素都会被转移并保存到字典里面,并且对象的编码也会从 intset 变为 hashtable。
官方的两个类型转换示例略。
集合命令的实现
因为集合键的值为集合对象,所以用于集合键的所有命令都是针对集合对象来构建的。 一部分集合键命令实现参考 一部分集合键命令
有序集合对象
有序集合的编码可以是 ziplist 或者 skiplist。
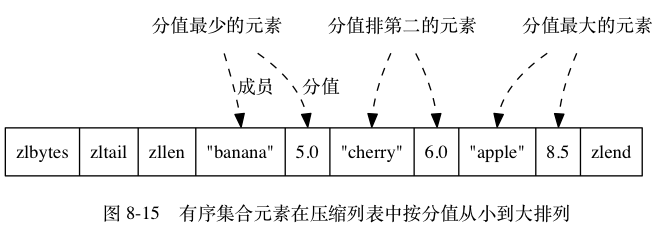
ziplist 编码的有序集合对象使用压缩列表作为底层实现,每个集合元素使用两个紧挨在一起的压缩列表节点来保存,第一个节点保存元素的成员(member),而第二个元素则保存元素的分值(score)。
压缩列表内的集合元素按分值从小到大进行排序,分值较小的元素被放置在靠近表头的方向,而分值较大的元素则被放置在靠近表尾的方向。
举个例子,如果我们执行以下 ZADD 命令,那么服务器将创建一个有序集合对象作为 price 键的值:
redis> ZADD price 8.5 apple 5.0 banana 6.0 cherry
(integer) 3
如果 price 键的值对象使用的是 ziplist 编码,那么这个值对象将会是图 8-14 所示的样子,而对象所使用的压缩列表则会是 8-15 所示的样子。
skiplist 编码的有序集合对象使用 zset 结构作为底层实现,一个 zset 结构同时包含一个字典和一个跳跃表:
typedef struct zset {
zskiplist *zsl;
dict *dict;
} zset;
zset 结构中的 zsl 跳跃表按分值从小到大保存了所有集合元素,每个跳跃表节点都保存了一个集合元素:跳跃表节点的 object 属性保存了元素的成员,而跳跃表节点的 score 属性则保存了元素的分值。通过这个跳跃表,程序可以对有序集合进行范围型操作,比如 ZRANK、ZRANGE 等命令就是基于跳跃表 API 来实现的。
除此之外 zset 结构中的 dict 字典为有序集合创建了一个从成员到分值的映射,字典中的每个键值对都保存了一个集合元素:字典的键保存了元素的成员,而字典的值则保存了元素的分值。通过这个字典,程序可以用 O(1) 复杂度查找给定成员的分值,ZSCORE 命令就是根据这一特性实现的,而很多其他有序集合命令都在实现的内部用到了这一特性。
有序集合每个元素的成员都是一个字符串对象,而每个元素的分值都是一个 double 类型的浮点数。值得一提的是,虽然 zset 结构同时使用跳跃表和字典来保存有序集合元素,但这两种数据结构都会通过指针来共享相同元素的成员和分值,所以同时使用跳跃表和字典来保存集合元素不会产生任何重复成员或者分值,也不会因此而浪费额外的内存。
TIP
为什么有序集合需要同时使用跳跃表和字典来实现?
在理论上来说,有序集合可以单独使用字典或者跳跃表的其中一种数据结构来实现,但无论单独使用字典还是跳跃表,在性能上对比起同时使用字典和跳跃表都会有所降低。
举个例子,如果我们只使用字典来实现有序集合,那么虽然以 O(1) 复杂度查找成员的分值这一特性会被保留,但是,因为字典以无序的方式来保存集合元素,所以每次在执行范围型操作。比如 ZRANK、ZRANGE 等命令时,程序都需要对字典保存的所有元素进行排序,完成这种排序需要至少 O(Nlog N) 时间复杂度,以及额外的 O(N) 内存空间(因为要创建一个数组来保存排序后的元素)。
另一方面,如果我们只使用跳跃表来实现有序集合,那么跳跃表执行范围型操作的所有优点都会被保留,但因为没有了字典,所以根据成员查找分值这一操作的复杂度将从 O(1) 上升为 O(log N) 。
因为以上原因, 为了让有序集合的查找和范围型操作都尽可能快地执行, Redis 选择了同时使用字典和跳跃表两种数据结构来实现有序集合。
举个例子,如果前面 price 键创建的不是 ziplist 编码的有序集合对象,而是 skiplist 编码的有序集合对象,那么这个有序集合对象将会是图 8-16 所示的样子,而对象所使用的 zset 结构将会是图 8-17 所示的样子。
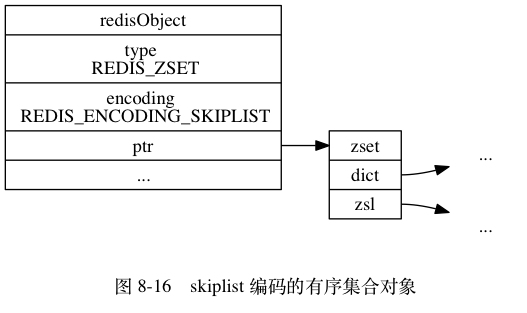
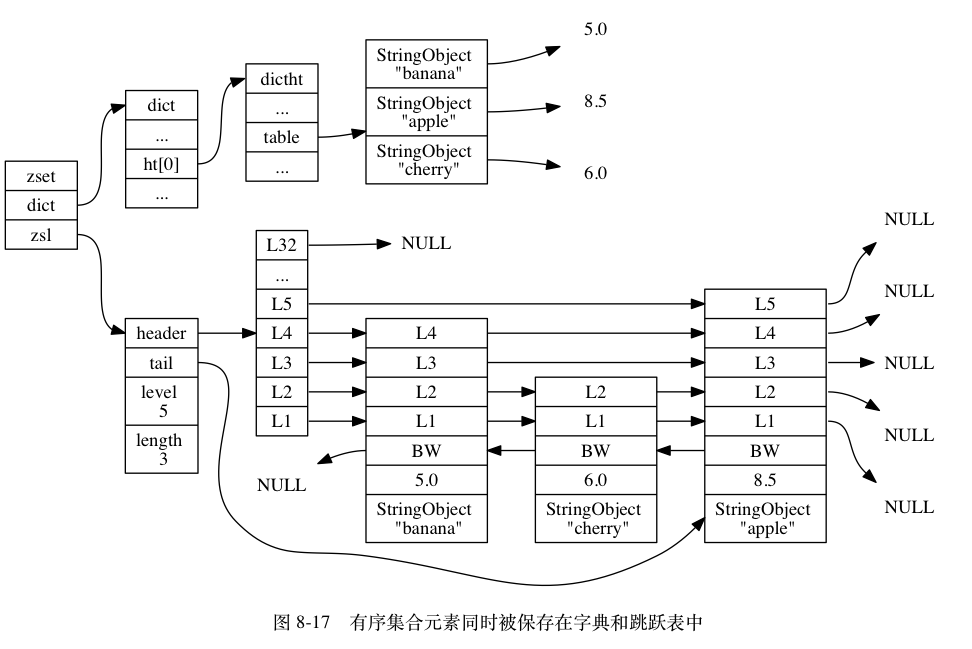
TIP
为了展示方便,图 8-17 在字典和跳跃表中重复展示了各个元素的成员和分值,但在实际中,字典和跳跃表会共享元素的成员和分值,所以并不会造成任何数据重复,也不会因此而浪费任何内存。
编码的转换
当有序集合对象可以同时满足以下两个条件时,对象使用 ziplist 编码:
- 有序集合保存的元素数量小于 128 个;
- 有序集合保存的所有元素成员的长度都小于 64 字节。
不能满足以上两个条件的有序集合对象将使用 skiplist 编码。
TIP
以上两个条件的上限值是可以修改的,具体请看配置文件中关于 zset-max-ziplist-entries 选项和 zset-max-ziplist-value 选项的说明。
对于使用 ziplist 编码的有序集合对象来说,当使用 ziplist 编码所需的两个条件中的任意一个不能被满足时,程序就会执行编码转换操作,将原本储存在压缩列表里面的所有集合元素转移到 zset 结构里面,并将对象的编码从 ziplist 改为 skiplist。
官方的两个类型转换示例略。
有序集合命令的实现
因为有序集合键的值为有序集合对象, 所以用于有序集合键的所有命令都是针对有序集合对象来构建的。 一部分有序集合键命令实现参考 一部分有序集合键命令
类型检查与命令多态
Redis 中用于操作键的命令基本上可以分为两种类型。
其中一种命令可以对任何类型的键执行,比如说 DEL 命令、EXPIRE 命令、RENAME 命令、TYPE 命令、OBJECT 命令,等等。
而另一种命令只能对特定类型的键执行, 比如说:
- SET、GET、APPEND、STRLEN 等命令只能对字符串键执行;
- HDEL、HSET、HGET、HLEN 等命令只能对哈希键执行;
- RPUSH、LPOP、LINSERT、LLEN 等命令只能对列表键执行;
- SADD、SPOP、SINTER、SCARD 等命令只能对集合键执行;
- ZADD、ZCARD、ZRANK、ZSCORE 等命令只能对有序集合键执行。
类型检查的实现
为了确保只有指定类型的键可以执行某些特定的命令,在执行一个类型特定的命令之前,Redis 会先检查输入键的类型是否正确,然后再决定是否执行给定的命令。
类型特定命令所进行的类型检查是通过 redisObject 结构的 type 属性来实现的:
- 在执行一个类型特定命令之前,服务器会先检查输入数据库键的值对象是否为执行命令所需的类型,如果是的话,服务器就对键执行指定的命令;
- 否则,服务器将拒绝执行命令,并向客户端返回一个类型错误。
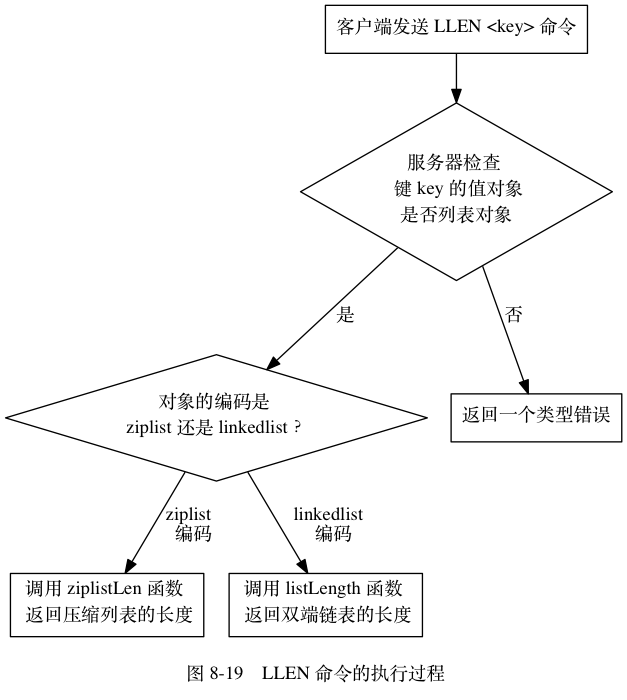
举个例子,对于 LLEN 命令来说:
- 在执行 LLEN 命令之前,服务器会先检查输入数据库键的值对象是否为列表类型,也即是,检查值对象 redisObject 结构 type 属性的值是否为 REDIS_LIST,如果是的话,服务器就对键执行 LLEN 命令;
- 否则的话,服务器就拒绝执行命令并向客户端返回一个类型错误。
其他类型特定命令的类型检查过程也和这里展示的 LLEN 命令的类型检查过程类似。
多态命令的实现
Redis 除了会根据值对象的类型来判断键是否能够执行指定命令之外,还会根据值对象的编码方式,选择正确的命令实现代码来执行命令。
举个例子,在前面介绍列表对象的编码时我们说过,列表对象有 ziplist 和 linkedlist 两种编码可用,其中前者使用压缩列表 API 来实现列表命令,而后者则使用双端链表 API 来实现列表命令。
现在,考虑这样一个情况,如果我们对一个键执行 LLEN 命令,那么服务器除了要确保执行命令的是列表键之外,还需要根据键的值对象所使用的编码来选择正确的 LLEN 命令实现:
- 如果列表对象的编码为 ziplist,那么说明列表对象的实现为压缩列表,程序将使用 ziplistLen 函数来返回列表的长度;
- 如果列表对象的编码为 linkedlist,那么说明列表对象的实现为双端链表,程序将使用 listLength 函数来返回双端链表的长度;
借用面向对象方面的术语来说,我们可以认为 LLEN 命令是多态(polymorphism)的:只要执行 LLEN 命令的是列表键,那么无论值对象使用的是 ziplist 编码还是 linkedlist 编码,命令都可以正常执行。
图 8-19 展示了 LLEN 命令从类型检查到根据编码选择实现函数的整个执行过程,其他类型特定命令的执行过程也是类似的。
实际上,我们可以将 DEL、EXPIRE、TYPE 等命令也称为多态命令,因为无论输入的键是什么类型,这些命令都可以正确地执行。
DEL、EXPIRE 等命令和 LLEN 等命令的区别在于,前者是基于类型的多态。一个命令可以同时用于处理多种不同类型的键,而后者是基于编码的多态。一个命令可以同时用于处理多种不同编码。
内存回收
因为 C 语言并不具备自动的内存回收功能,所以 Redis 在自己的对象系统中构建了一个引用计数(reference counting)技术实现的内存回收机制,通过这一机制,程序可以通过跟踪对象的引用计数信息,在适当的时候自动释放对象并进行内存回收。
每个对象的引用计数信息由 redisObject 结构的 refcount 属性记录:
typedef struct redisObject {
// ...
// 引用计数
int refcount;
// ...
} robj;
对象的引用计数信息会随着对象的使用状态而不断变化:
- 在创建一个新对象时,引用计数的值会被初始化为 1;
- 当对象被一个新程序使用时,它的引用计数值会被增一;
- 当对象不再被一个程序使用时,它的引用计数值会被减一;
- 当对象的引用计数值变为 0 时,对象所占用的内存会被释放。
表 8-12 列出了修改对象引用计数的 API,这些 API 分别用于增加、减少、重置对象的引用计数。
| 函数 | 作用 |
|---|---|
| incrRefCount | 将对象的引用计数值增一。 |
| decrRefCount | 将对象的引用计数值减一, 当对象的引用计数值等于 0 时, 释放对象。 |
| resetRefCount | 将对象的引用计数值设置为 0 , 但并不释放对象, 这个函数通常在需要重新设置对象的引用计数值时使用。 |
对象的整个生命周期可以划分为创建对象、操作对象、释放对象三个阶段。
对象共享
除了用于实现引用计数内存回收机制之外,对象的引用计数属性还带有对象共享的作用。
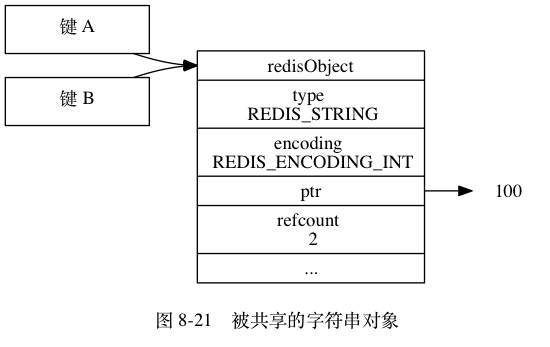
举个例子,假设键 A 创建了一个包含整数值 100 的字符串对象作为值对象。如果这时键 B 也要创建一个同样保存了整数值 100 的字符串对象作为值对象, 那么服务器有以下两种做法:
- 为键 B 新创建一个包含整数值 100 的字符串对象;
- 让键 A 和键 B 共享同一个字符串对象。
以上两种方法很明显是第二种方法更节约内存。在 Redis 中,让多个键共享同一个值对象需要执行以下两个步骤:
- 将数据库键的值指针指向一个现有的值对象;
- 将被共享的值对象的引用计数增一。
举个例子,图 8-21 就展示了包含整数值 100 的字符串对象同时被键 A 和键 B 共享之后的样子,可以看到,除了对象的引用计数从之前的 1 变成了 2 之外,其他属性都没有变化。
共享对象机制对于节约内存非常有帮助,数据库中保存的相同值对象越多,对象共享机制就能节约越多的内存。
目前来说,Redis 会在初始化服务器时,创建一万个字符串对象,这些对象包含了从 0 到 9999 的所有整数值,当服务器需要用到值为 0 到 9999 的字符串对象时, 服务器就会使用这些共享对象,而不是新创建对象。
TIP
创建共享字符串对象的数量可以通过修改 redis.h/REDIS_SHARED_INTEGERS 常量来修改。
举个例子,如果我们创建一个值为 100 的键 A ,并使用 OBJECT REFCOUNT 命令查看键 A 的值对象的引用计数,我们会发现值对象的引用计数为 2。
另外,这些共享对象不单单只有字符串键可以使用,那些在数据结构中嵌套了字符串对象的对象(linkedlist 编码的列表对象、hashtable 编码的哈希对象、 hashtable 编码的集合对象、以及 zset 编码的有序集合对象)都可以使用这些共享对象。
TIP
为什么 Redis 不共享包含字符串的对象?
当服务器考虑将一个共享对象设置为键的值对象时,程序需要先检查给定的共享对象和键想创建的目标对象是否完全相同,只有在共享对象和目标对象完全相同的情况下,程序才会将共享对象用作键的值对象,而一个共享对象保存的值越复杂,验证共享对象和目标对象是否相同所需的复杂度就会越高,消耗的 CPU 时间也会越多:
- 如果共享对象是保存整数值的字符串对象,那么验证操作的复杂度为 O(1);
- 如果共享对象是保存字符串值的字符串对象,那么验证操作的复杂度为 O(N);
- 如果共享对象是包含了多个值(或者对象的)对象,比如列表对象或者哈希对象,那么验证操作的复杂度将会是 O(N^2)。
因此,尽管共享更复杂的对象可以节约更多的内存,但受到 CPU 时间的限制,Redis 只对包含整数值的字符串对象进行共享。
对象的空转时长
除了前面介绍过的 type、encoding、ptr 和 refcount 四个属性之外,redisObject 结构包含的最后一个属性为 lru 属性,该属性记录了对象最后一次被命令程序访问的时间:
typedef struct redisObject {
// ...
unsigned lru:22;
// ...
} robj;
OBJECT IDLETIME 命令可以打印出给定键的空转时长,这一空转时长就是通过将当前时间减去键的值对象的 lru 时间计算得出的:
redis> SET msg "hello world"
OK
# 等待一小段时间
redis> OBJECT IDLETIME msg
(integer) 20
# 等待一阵子
redis> OBJECT IDLETIME msg
(integer) 180
# 访问 msg 键的值
redis> GET msg
"hello world"
# 键处于活跃状态,空转时长为 0
redis> OBJECT IDLETIME msg
(integer) 0
TIP
OBJECT IDLETIME 命令的实现是特殊的,这个命令在访问键的值对象时,不会修改值对象的 lru 属性。
除了可以被 OBJECT IDLETIME 命令打印出来之外,键的空转时长还有另外一项作用:如果服务器打开了 maxmemory 选项,并且服务器用于回收内存的算法为 volatile-lru 或者 allkeys-lru,那么当服务器占用的内存数超过了 maxmemory 选项所设置的上限值时,空转时长较高的那部分键会优先被服务器释放,从而回收内存。
配置文件的 maxmemory 选项和 maxmemory-policy 选项的说明介绍了关于这方面的更多信息。